

DeepSeek R1 震撼登场:挑战 OpenAI,开启 AI 推理开源普惠新时代
2025年1月20日,人工智能领域迎来了一位强有力的竞争者——DeepSeek R1。这款由深度求索公司推出的新一代推理大模型,以其卓越的性能和开源的生态布局,迅速引起了业界的广泛关注。
一、性能卓越,比肩OpenAI o1
DeepSeek R1在后训练阶段大规模使用了强化学习技术,即使在仅有极少标注数据的情况下,也能极大提升模型的推理能力。在数学、代码、自然语言推理等任务上,其性能与OpenAI的o1正式版相当。例如,在GSM8K数学推理任务中,DeepSeek R1取得了92.3%的成绩,与OpenAI o1持平;在CodeX代码生成任务中,也达到了89.7%的高分。这标志着DeepSeek R1在推理性能上达到了国际顶尖水平。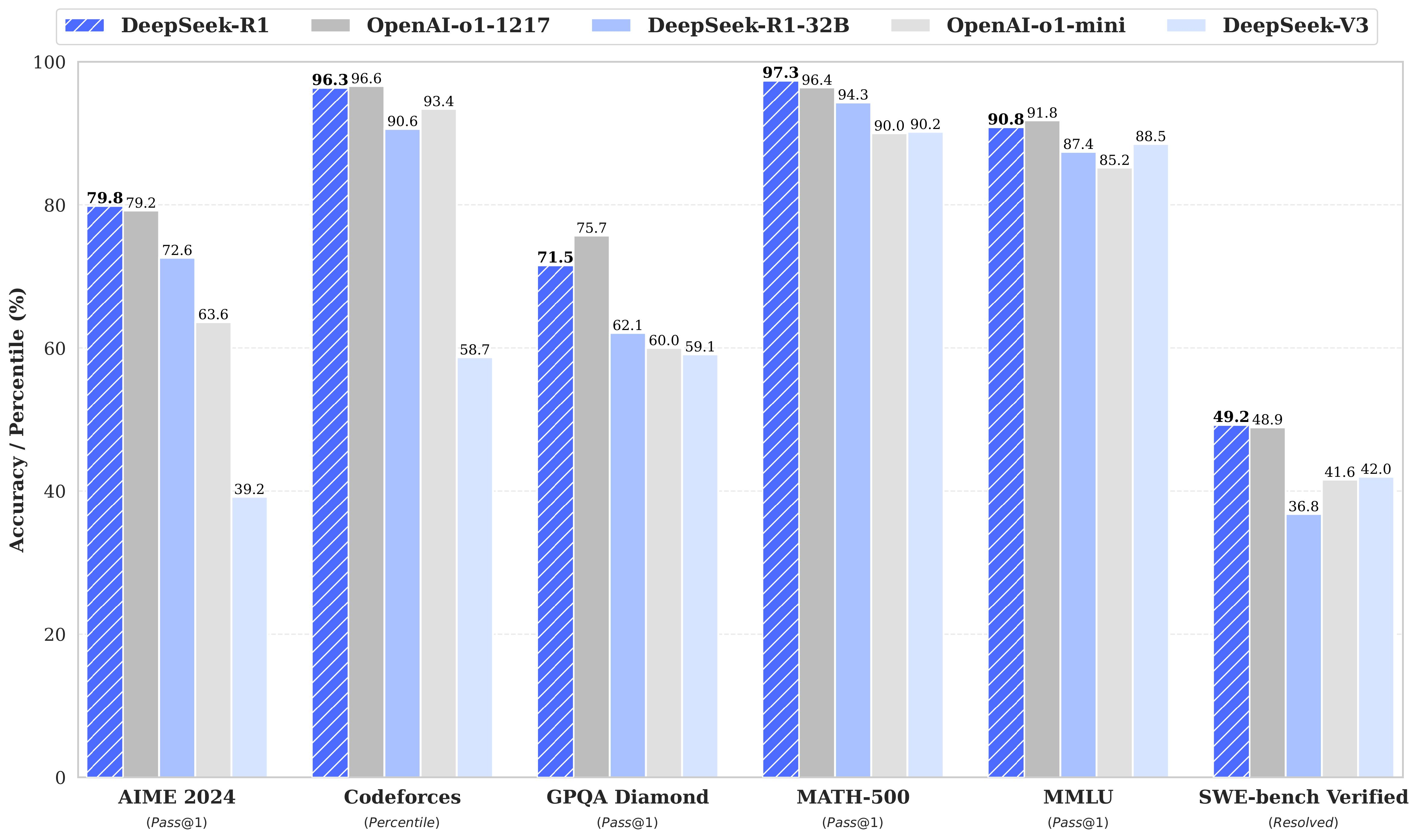
二、开源生态,推动技术创新
DeepSeek R1遵循MIT开源协议,允许用户通过蒸馏技术借助R1训练其他模型。这种开源策略不仅降低了开发者的使用门槛,还促进了技术社区的交流与创新。DeepSeek R1的模型权重和训练框架全部开源,为开发者提供了极大的便利。此外,DeepSeek还提供了完整的思维链API接口,用户可以通过设置model=’deepseek-reasoner’来调用,进一步拓展了模型的应用场景。
三、多场景应用,全面覆盖
DeepSeek R1不仅在技术上取得了突破,还在应用场景上实现了全面覆盖。用户可以通过DeepSeek官网或官方App体验最新的推理模型,完成各类复杂的推理任务。DeepSeek R1还支持企业级API,提供128k上下文拼接功能,满足企业级应用的需求。此外,DeepSeek R1的API服务定价也非常具有竞争力,每百万输入tokens仅需1元(缓存命中)/4元(缓存未命中),每百万输出tokens为16元。
四、研究方向转变
算法效率和资源优化:DeepSeek-R1的成功凸显了算法效率和资源优化在AI开发中越来越重要的地位。与仅仅依赖 brute-force scaling来提高性能的做法不同,DeepSeek通过大幅减少资源数量就实现了高性能,从而挑战了传统上更大规模模型和数据集总是更占优的观念。
训练方法创新:DeepSeek-R1的开发采用了纯强化学习,这与其标准做法大相径庭。 DeepSeek-R1-Zero——该模型早期版本,在采用强化学习后展露出了惊人推理行为,为模型训练开辟了新思路,可能进一步推动人工智能研究的发展。
五、蒸馏小模型,性能超群
DeepSeek R1通过动态知识蒸馏技术,能够将大模型的推理能力高效地迁移到小模型中。具体来说,研究团队使用DeepSeek R1生成的80万条推理数据样本,对较小的基础模型(如Qwen和Llama系列)进行微调,从而创建了多个蒸馏模型。这些蒸馏模型在推理能力上实现了显著提升,甚至超过了在这些小模型上直接进行强化学习的效果。例如,DeepSeek-R1-Distill-Qwen-7B在AIME 2024测试中取得了55.5%的成绩,超越了QwQ-32B-Preview。
降低计算成本
蒸馏模型比原始的DeepSeek R1模型更小,计算效率更高,使其更容易在资源受限的环境中部署。这对于在移动设备或边缘计算系统中部署模型特别有用。例如,DeepSeek-R1-Distill-Qwen-32B在AIME 2024上达到了72.6%的Pass@1,在MATH-500上达到了94.3%的Pass@1,其表现明显优于其他开源模型。
开源与普惠
DeepSeek团队开源了多个基于不同规模的Qwen和Llama架构的蒸馏模型,包括DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Qwen-14B、DeepSeek-R1-Distill-Qwen-32B、DeepSeek-R1-Distill-Llama-8B和DeepSeek-R1-Distill-Llama-70B。这些开源模型允许研究人员和开发人员在各种应用程序中使用和构建它们,推动了AI技术的民主化和普惠化。
DeepSeek R1 重磅发布冲击美国市场
技术行业
- 挑战美国科技巨头:DeepSeek R1在第三方测试中展示了与OpenAI最新模型(如o1)相媲美或甚至超越的性能,这让美国科技公司在竞争优势方面陷入了担忧。DeepSeek R1使用非美出口管制的Nvidia H800芯片实现了与OpenAI模型相当的性能。
- 成本效益和开源可及性:该模型的成本效益和开源性质使其成为变革性工具。根据深度求索的说法,他们以5576万美元的预算(约4.2亿人民币)训练了R1,使用了2800万个GPU小时的中端Nvidia H800 GPU。这与美国公司为 proprietary AI模型投入数十亿美元形成了鲜明对比,引发了投资者对美国科技公司高成本、高密集型资源策略的质疑。
- 创新和适应:如今,美国科技公司面临压力,必须在创新和优化运营方面做出努力以保持竞争优势,包括借鉴DeepSeek的架构、训练框架和硬件优化。
金融市场
- 股票抛售:DeepSeek R1的发布引发了美国科技股的大规模抛售。2025年1月27日,英伟达(Nvidia)的股价下跌约17%,导致市场市值蒸发近6000亿美元(CNBC报道为美国历史上最大单日跌幅)。此外,包括博通(Broadcom)在内的其他AI相关股票也下跌逾10%。
- 估值重审:投资者重新评估了AI相关公司高估的合理性,鉴于DeepSeek能够以成本分之一的价格生产具有竞争力的技术。这促使对大多数“七大战马”公司(Magnificent Seven)估值过高的假设进行了重新评估。


能源行业
- 能耗影响:据报道,DeepSeek R1在能耗方面比先进芯片约少50%,这意味着其在AI数据中心中的应用可能将降低一半的电力需求。
- 市场反应:尽管整体市场抛售引发连锁反应,但对冲所(Mizuho)维持其对美国天然气价格的看法不变,并将其归因于对科技公司股价影响的过度担忧。不过,该机构也指出了在遵守所有相关法规和标准方面可能面临的技术挑战。
政策与监管
- 国家安全关切:深度求索表示,该开源模型可能会被用于支持或促进恶意活动,因此美国政府需对其进行审查。此外,该公司的高管还强调了对AI技术扩散的担忧。
- 挑战美国主导地位:DeepSeek-R1的发布引发了对AI开发效率的讨论,尤其是在美中两国之间对AI芯片出口管制背景下。它挑战了只有拥有最新硬件才能在人工智能领域引领创新这一观念,强调资源合理利用和创新性训练方法可取得世界级成果。DeepSeek近期的产品发布,尤其是推出DeepSeek-R1,恰逢时机,表现出强烈地缘政治色彩。该模型的发布恰逢美中AI竞争白热化之际,凸显其战略意义。
公共与媒体反应
- 媒体关注:由于DeepSeek R1在多个平台上获得了广泛传播,其在社交媒体上的公众知名度显著提升。例如,在推特上,该话题在过去两周内的互动量已超过200万条。
DeepSeek R1的发布,无疑是人工智能领域的一次重大突破。它不仅在性能上比肩国际顶尖模型,还通过开源生态和多场景应用,为开发者和企业用户提供了强大的技术支持。我们有理由相信,DeepSeek R1将推动AI推理技术的进一步发展,开启通用人工智能普惠化的新纪元。
- Title: DeepSeek R1 震撼登场:挑战 OpenAI,开启 AI 推理开源普惠新时代
- Author: Jason Yang
- Created at : 2025-01-29 11:00:00
- Updated at : 20245-01-29 11:10:00
- Link: https://blog.jason-yang.top/2025/01/29/DeepSeek R1 发布/
- License: This work is licensed under CC BY-NC-SA 4.0.


